
Here you will find updates on our results.
Application domain targets and requirements
Based on several representative application case studies, a report has been prepared to summarize the main application domain characteristics and their requirements on time-scale ranges. This analysis substantiates our claim that up to 9 orders of magnitude of time scales need to be supported from msec up to months or even years.
Toward a theory of timescales in neuromorphic computing
Different sorts of “timescales” are relevant for the co-design of neuromorphic hardware systems and the information processing that can (or cannot) be done on them. The main findings are a differentiation between causal timescales (effective in the hardware basis) and phenomenal timescales (descriptive for the information processing). Causal timescales are typically formalized by time constants in differential equations, whereas phenomenal timescales describe desired performance aspects with regards to speed, reactivity, and memory.
The picture illustrates a method to speed up or slow down the oscillatory dynamics of a recurrent neural network (RNN), by controlling the state space region in which the dynamics is allowed to unfold. A control parameter ‘speed’ is here varied from slow to fast. The first two principal components of the RNN dynamics are plotted, revealing that slow oscillations visit different state space regions than fast ones. This is one of about twenty algorithmic timescales management mechanisms surveyed in deliverable D1.2.
Materials
- Deliverable D1.2 (timescale theory discussion and survey of algorithmic timescale management methods, 50 pages)
- H.Jaeger, F. Catthoor (2022): Timescales: the choreography of classical and unconventional computing. arxiv preprint (extended 80 pp version of D1.2)
Toward a general theory of computing in unconventional physical hardware
Beyond timescales, other crucial aspects of designing computing systems on the basis of unconventional (non-digital) hardware include stochasticity, unclocked parallelism, non-stationarity (from temperature dependence to aging) or device mismatch. In order to found a systematic engineering discipline, a formal theory is needed, which gives precise and comprehensive guidance similar to the guidance given by the classical symbolic-computing textbook theory to digital computer engineering. Research in MemScales (in exchange with other EU projects and partners) has worked out a principled strategy to arrive at such a general theory body for neuromorphic and other unconventional computing engineering.
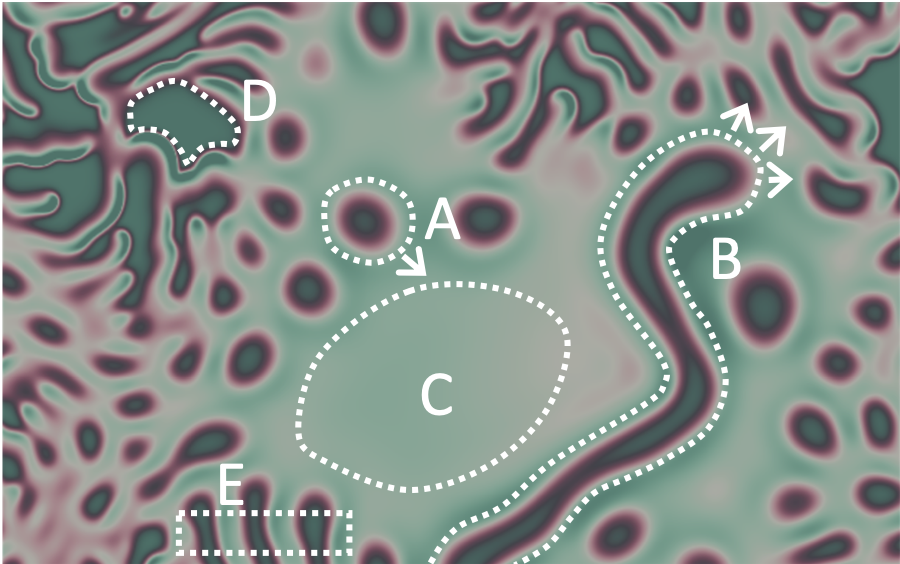
The image shows physical phenomena in a continuous 2D spatial substrate that could be used for computing: moving solitons (A) and filaments (B), neutral (C) and excited (D) fields, periodic structures (E). A general theory would be able to capture all such sorts of phenomena in a unifying formal representation. Figure taken from Jaeger/Noheda/vd Wiel (2023).
Materials
- H. Jaeger (2021): Toward a Generalized Theory Comprising Digital, Neuromorphic, and Unconventional Computing. Neuromorphic Computing and Engineering 1(1) (open access article)
- Deliverable D1.5: Theory-building for unconventional computing (32 pages)
- H. Jaeger, B. Noheda, W. G. van der Wiel (2023): Toward a formal theory for computing machines made out of whatever physics offers. Nature Communications 14, 4911 (open access article)
Nonlinear Dynamics of RRAM Weight Update for Efficient SNN Unsupervised Training
The training of neural networks requires huge amount of energy and time, both of which can be improved by the implementation of analog nonvolatile synaptic elements, like analog resistive memories (RRAMs) in neuromorphic architectures. To this aim, though, the RRAM conductance (or weight) update is thought to be crucial in determining the success of a training procedure. We showed that, for the training of a SNN through an unsupervised Spike Timing Dependent Plasticity protocol, a specific class of nonlinear weight update optimizes the trade-off between training time and final classification accuracy. A single layer SNN is trained to classify handwritten MNIST digits (see top panel of the figure). A single layer SNN was trained to classify handwritten MNIST digits (see top panel of the figure).
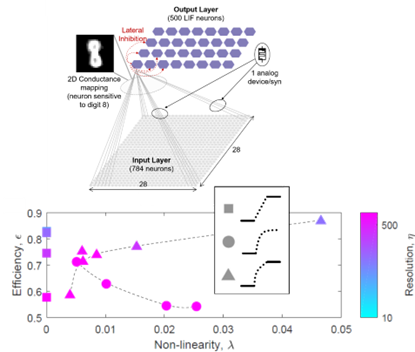
We showed that a nonlinear weight update with defined boundaries (triangles in the bottom panel of the figure) can sustain accuracy close to the maximum achieved (≈83%) with short training duration through high nonlinearity and low precision (90 conductance steps) compared to synapses with nonlinear weight update and asymptotic approach to the boundaries (circles) and those with linear update (squares).
Publication:
S. Brivio, Denys R. B. Ly, E. Vianello and S. Spiga, Front. Neurosci. 15 580909 (2021)
Modeling of the analog dynamics of RRAM devices
Analog or deep multilevel nonvolatile RRAM devices are a valuable opportunity for the energy-efficient implementation of synaptic weights in neuromorphic architectures. However, challenges are still there in device development and in the design of architectures with programming operations adapted to device peculiarities. In this context, the modeling of the electrical device behaviour is fundamental in supporting the understanding of the physics behind the device operation, the further technology development and the device integration into neuromorphic architecture.
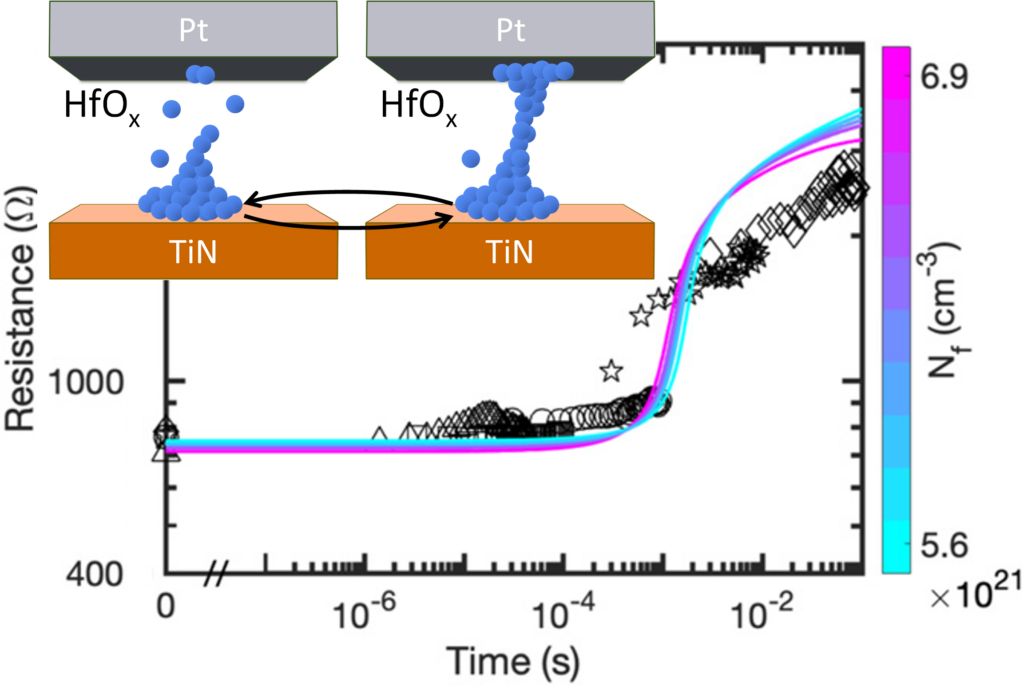
In this context, we developed a compact model of filamentary RRAM device able to catch the device analogue dynamics and variability of prototypical Pt/HfO2/TiN devices. The model describes the switching operation of the device in terms of a modulation of the concentration of oxygen vacancies within a filamentary region by virtue of drift and diffusion processes activated by electric field, and Joule heating.
Publication:
F. Vaccaro, S. Brivio, S. Perotto, A.G. Mauriand S. Spiga, Neuromorph. Comp. Engin. 2 021003 (2022)
Multi-timescale Thin-Film Transistor Neuron

The advantages of having several different bio-compatible timescales can be more readily leveraged when neuromorphic hardware itself can generate them. During MeM-Scales Indium Gallium Zinc Oxide (IGZO) Thin-Film Transistors (TFTs) were explored as a means of generating very slow timescales.
The extremely low leakage currents of IGZO TFTs were accurately evaluated, exploited and controlled to finally fabricate a neuron capable of firing with an extremely wide range of slow bio-compatible timescales. The firing rate range of the multi-timescale TFT neuron seen in the figure is 7 orders of magnitude wide from mH to µH. These results show that transistors made out of materials such as IGZO can compensate for some of the shortcomings of Silicon CMOS transistors and suggest that hybrid solutions (along with the Non-Volatile Memory technologies also explored) could be a viable option for future spiking neuromorphic systems.
Publication (in progress):
“A multi-timescale Indium Gallium Zinc Oxide TFT neuron towards hybrid solutions for spiking neuromorphic applications.” M. Velazquez Lopez, B. Linares-Barranco, J. Lee, H. Erfanijazi, F. Catthoor and K. Myny
Neuromorphic object localization
In the era of pervasive computing, an increasing number of everyday objects are becoming equipped with microprocessors to enhance the smooth functioning of our lives. To accomplish this, these systems must operate continuously, conserving energy while extracting valuable information from noisy and often incomplete data collected from various sensors in real-time. Real-world sensory-processing applications demand computer systems that are compact, offer low latency, and consume minimal power.
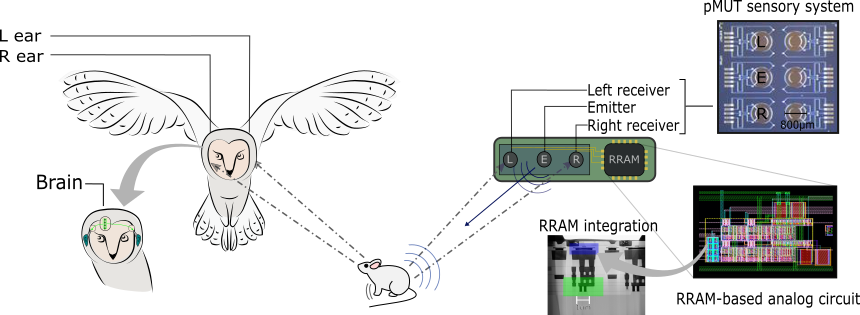
Hybrid memristive-Complementary Metal-Oxide Semiconductor (CMOS) neuromorphic architectures, renowned for their in-memory event-driven computing capabilities, serve as an ideal hardware foundation for such tasks. We have developed an event-driven object localization system as part of the MeMScales project. This system integrates state-of-the-art piezoelectric ultrasound transducer sensors with a neuromorphic computational map based on resistive memories. The neuromorphic computational map incorporates coincidence detectors, delay line circuits, neurons, and synapse circuits with time constants ranging from tens of microseconds to a few milliseconds.
We utilized experimental data to calibrate our system-level simulations, enabling us to estimate the angular resolution and energy efficiency of the object localization model. The results demonstrated significantly greater energy efficiency compared to a microcontroller performing the same task.
Publication:
Moro, F., Hardy, E., Fain, B. et al. Neuromorphic object localization using resistive memories and ultrasonic transducers. Nat Commun 13, 3506 (2022). https://doi.org/10.1038/s41467-022-31157-y
Memristive Self-organizing Spiking Recurrent Neural Network
Computing, as we know it, is done using digital computers that reduce the dynamic range of computation to rails (power and ground) to gain noise immunity and perform robust computation. However, the brain has a substrate that is far from perfect, and neurons and synapses are highly noisy and variable.
Micro-organisms have evolved over the course of millions of years resulting in the intelligent animals that we are, interacting with the real world while performing “computation” using these noisy elements. How has this intelligence emerged? The answers to these questions are mostly unknown. But there is neuroscientific evidence that neuronal systems in the brain dynamically store and organize incoming information into a web of memory representations which is essential for the generation of complex behaviors. This memory formation is as a result of a combination of learning rules at different time scales.
Inspired by these mechanisms, we have designed and demonstrated an adaptive hardware architecture, “MEMSORN”. MEMSORN takes advantage of the spatial and temporal noise of the physics of the substrate to self-organize its structure to the incoming input and learn a sequence. Specifically, we take advantage of the inherent noise of the resistive memory, an emerging memory technology, to learn the structure of a sequence without any supervision. The unsupervised learning rules are directly derived from the statistical characteristics of the available hardware, and thus learning emerges from the substrate itself. Therefore, this work represents a fundamental step toward the design of future brain-inspired intelligent devices and applications. Specifically, these findings have applications in adapting the edge devices to the unique users. For example, adapting wearable devices to each patient, or the smart home devices to the users’ accent, habits, or preferences.
Publication:
Payvand, M., Moro, F., Nomura, K. et al. Self-organization of an inhomogeneous memristive hardware for sequence learning. Nat Commun 13, 5793 (2022). https://doi.org/10.1038/s41467-022-33476-6
On the performance and hardware efficiency of synaptic-delay parameterization of (Spiking) Neural Network models
The role of axonal synaptic delays in the efficacy and performance of artificial neural networks has been largely unexplored. In step-based analog-valued neural network models (ANNs), the concept is almost absent. In their spiking neuroscience-inspired counterparts, there is hardly a systematic account of their effects on model performance in terms of accuracy and number of synaptic operations.
We have developed a methodology of training deep (spiking) Neural Network models parameterized with synaptic (axonal/dendritic) delays, to efficiently solve machine learning tasks on data with rich temporal dependencies. We have conducted an empirical study of the effects of axonal delays on model performance during inference for the Adding and Memory benchmark tasks, the Spiking Heidelberg Digits, Spiking Commands, and DVS gesture datasets (among other); where we consistently see that incorporating axonal delays instead of explicit recurrent synapses achieve state-of-the-art performance while needing less than half trainable parameters and exhibiting much sparser activations.
Additionally, we estimate the required memory in terms of total parameters and energy consumption of accommodating such delay-trained models on a modern neuromorphic accelerators. based on reference GF-22nm FDX CMOS technology. A reduced parameterization, that incorporates axonal delays, leads to approximately 90% energy and memory reduction in digital hardware implementations for a similar performance in the SHD task.
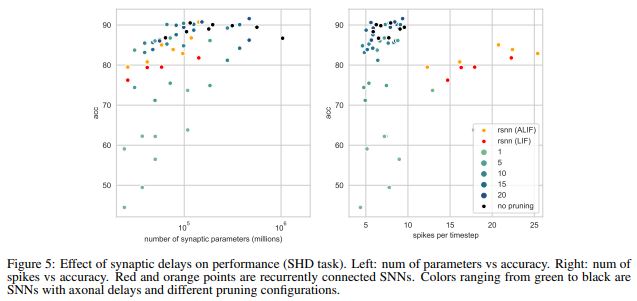
Publication:
Alberto Patiño-Saucedo; Amirreza Yousefzadeh; Guangzhi Tang; Federico Corradi; Bernabé Linares-Barranco; Manolis Sifalakis. An empirical study on the efficiency of Spiking Neural Networks with axonal synaptic delays and algorithm-hardware benchmarking. IEEE International Symposium on Circuits and Systems (ISCAS) 2023